library(dplyr)
library(tidytext)
library(ggplot2)
library(highcharter)
# Cargamos el tema de ggplot del blog El arte del dato
theme_set(theme_elartedeldato())
# Cargamos el discurso transcrito
discurso <- readLines('discurso-pedro-sanchez.txt')
# Alamcenamos como dataframe el texto
n <- length(discurso)
df_discurso <- tibble(line = 1:n, text = discurso)
# Eliminamos las stopwords y añadimos otras utiliadas en el discurso
stop_words_es <- get_stopwords('es')
new_stop_words <- c('hacer','vamos','pues', 'creo', 'ser', 'va','también','solo','si','ello', 'más', 'sí', 'será' ,'aún')
stop_words_es <- tibble(word = c(stop_words_es$word, new_stop_words))
df_discurso |>
unnest_tokens(word, text) |>
anti_join(stop_words_es) -> df_discurso_wordEsta mañana hemos escuchado el discurso de investidura del candidato a la Presidencia del Gobierno de España, Pedro Sánchez. El discurso fue recogido en directo por algunos medios. En concreto hemos utilizado el editado por La Moncloa que puedes encontrar aquí. En este post analizaremos los términos más empleados por el candidato así como la evolución del discurso en función del tono del mismo.
Una vez cargado y editado el texto, visualizamos las palabras más utilizadas durante el discurso. Para ello utilizaremos un gráfico de barras.
df_discurso_word |>
count(word, sort = TRUE) -> df_discurso_count
df_discurso_count |>
filter(n > 15) |>
mutate(word = reorder(word, n)) |>
ggplot(aes(word, n)) +
geom_col(fill = "#e30614") +
coord_flip() +
labs(title = "Palabras más utilizadas en el discurso \nde investidura",
subtitle = "Intervención de Pedro Sánchez",
x = "", y = "")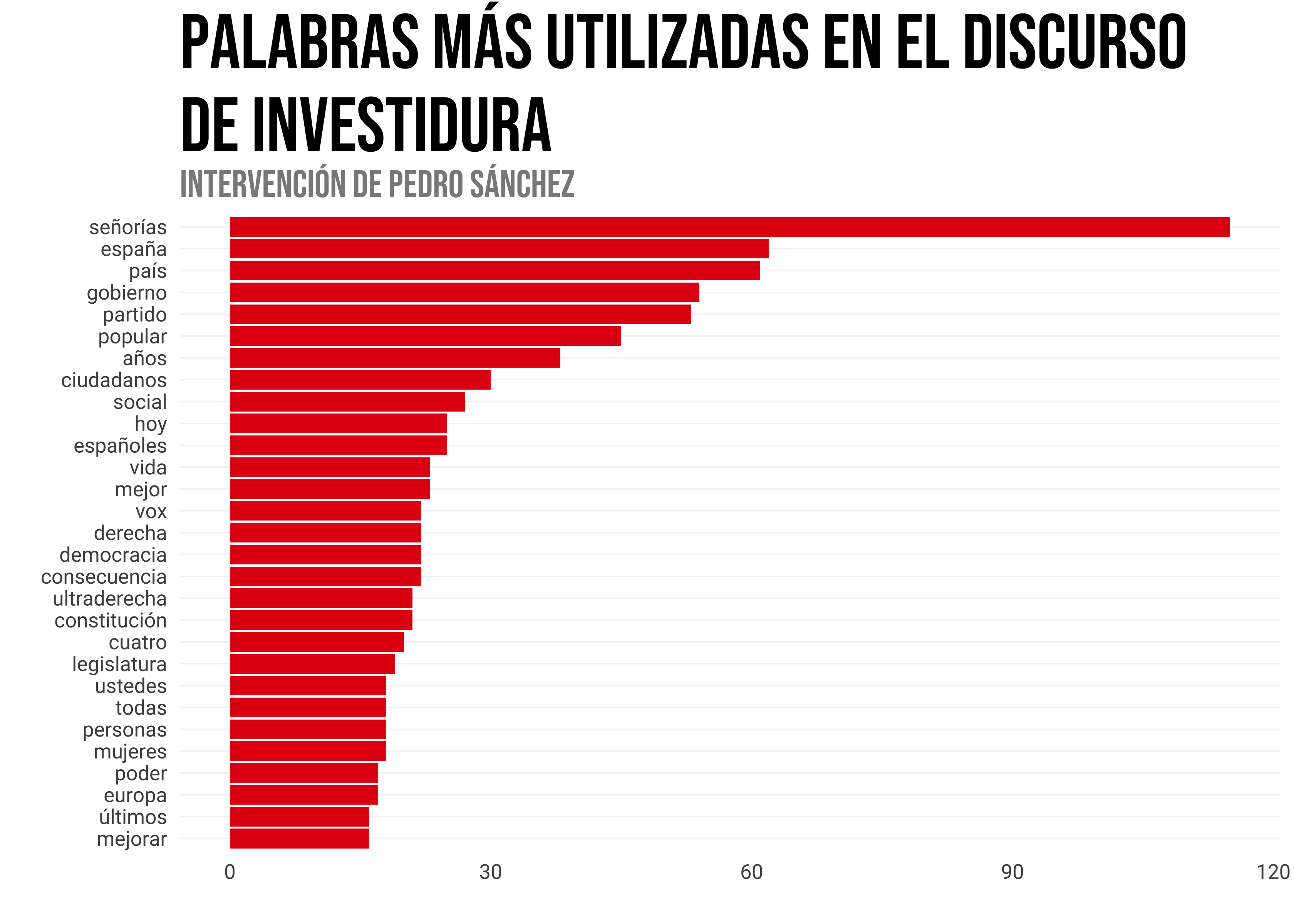
Por otro lado, otra forma común de visualizar frecuencias de términos en un texto, es a través del gráfico de wordcloud.
set.seed(10)
df_discurso_count |>
with(wordcloud::wordcloud(min.freq = 7,
words = word,
freq = n,
random.order = FALSE,
family = "Bebas Neue"))
Nota
Ten en cuenta que no todas las palabras se muestran, puesto que se han filtrado aquellas de frecuencia más baja.
Puedes consultar la lista entera aquí:
reactable::reactable(df_discurso_count, sortable = FALSE, showPageSizeOptions = TRUE,
fullWidth = FALSE, height = "auto",
columns = list(word = reactable::colDef(name = "Palabra", filterable = TRUE)),
style = list(fontFamily = "Bebas Neue"))Análisis de sentimiento
Pasamos ahora a analizar el sentimiento de cada una de las frases del discurso desde un punto de vista general. Para ello utilizaremos la librería de R syuzhet.
Advertencia
Este análisis sólo pretende mostrar un ejemplo de visualización de sentimiento de texto, pero en ningún caso está supervisado por un lingüista experta/o.
# Calculamos sentimiento en cada frase
syuzhet::get_sentiment(discurso, method = "nrc", language = "spanish") -> sentimiento
df_sentimiento <- data.frame(sentimiento)
df_sentimiento$frase <- discurso
df_sentimiento$momento <- 1:n
hchart(
df_sentimiento,
type = "area",
hcaes(x = momento, y = sentimiento),
zones = list(
list(value = 0,
color= '#ff6968',
fillColor = list(linearGradient = list(x1 = 0, y1 = 0, x2 = 0, y2 = 1),
stops = list(list(0, paste0('#ff6968', '00')), list(1, '#ff6968')))),
list(color='#94caae',
fillColor = list(linearGradient = list(x1 = 0, y1 = 0, x2 = 0, y2 = 1),
stops = list(list(0, '#94caae'), list(1, paste0('#94caae',"00")))))
)
) |>
hc_tooltip(
headerFormat = "Sentimiento: {point.y}<br>",
pointFormat = "{point.frase}"
) |>
hc_title(text = "<b>Análisis de sentimiento</b>") |>
hc_subtitle(text = "<i>Discurso de investidura Pedro Sánchez</i>") |>
hc_credits(enabled = TRUE, text = "http://elartedeldato.com")Como nota final, aclarar que el análisis de sentimiento sirve como herramienta de apoyo para extraer conclusiones generales sobre el tono del discurso palabra a palabra, no tanto del fondo del mismo que debe ser estudiado en detalle por expertos de la materia.