df0 <- read.csv('accidentes_ferroviarios.csv')Realizar un gráfico puede ser una tarea sencilla a priori. Existen multitud de programas que nos permiten representar datos de forma guiada, sin grandes complicaciones. Sin embargo, cuando tratamos de que una visualización transmita un mensaje concreto, la tarea se vuelve más complicada.
Por ello, en este post daremos 5 consejos prácticos para que tu gráfico sea efectivo y dé lugar a una visualización clara y concisa.
Pogamos por ejemplo, que tratamos de explicar el descenso del número de accidentes ferroviarios en los últimos años. Para ello, utilizaremos los datos de Fomento sobre accidentes de tren de la Red Ferroviaria de Interés General por tipo de accidente desde 2009 hasta 2019. Tengamos en cuenta que no toda la información de que la disponemos es necesario mostrarla.
library(ggplot2)
library(rcartocolor)
library(hrbrthemes)
ggplot(df0, aes(x=year, y=valor, color=nombreTipoAccidenFer)) +
geom_point() +
geom_line() +
scale_x_continuous(breaks=2009:2019) +
scale_color_carto_d(palette = 'Magenta') +
scale_fill_carto_d(palette = 'Magenta') +
facet_wrap('nombreValoracionAcciden') +
theme_ipsum() +
theme(legend.position='bottom') +
labs(title='Evolución del número de accidentes ferroviarios \nen la Red Ferroviaria de Interés General por tipo de accidente', caption='Fuente: Agencia Estatal de Seguridad Ferroviaria (AESF)',
color='Tipo Accidente') -> p0
p0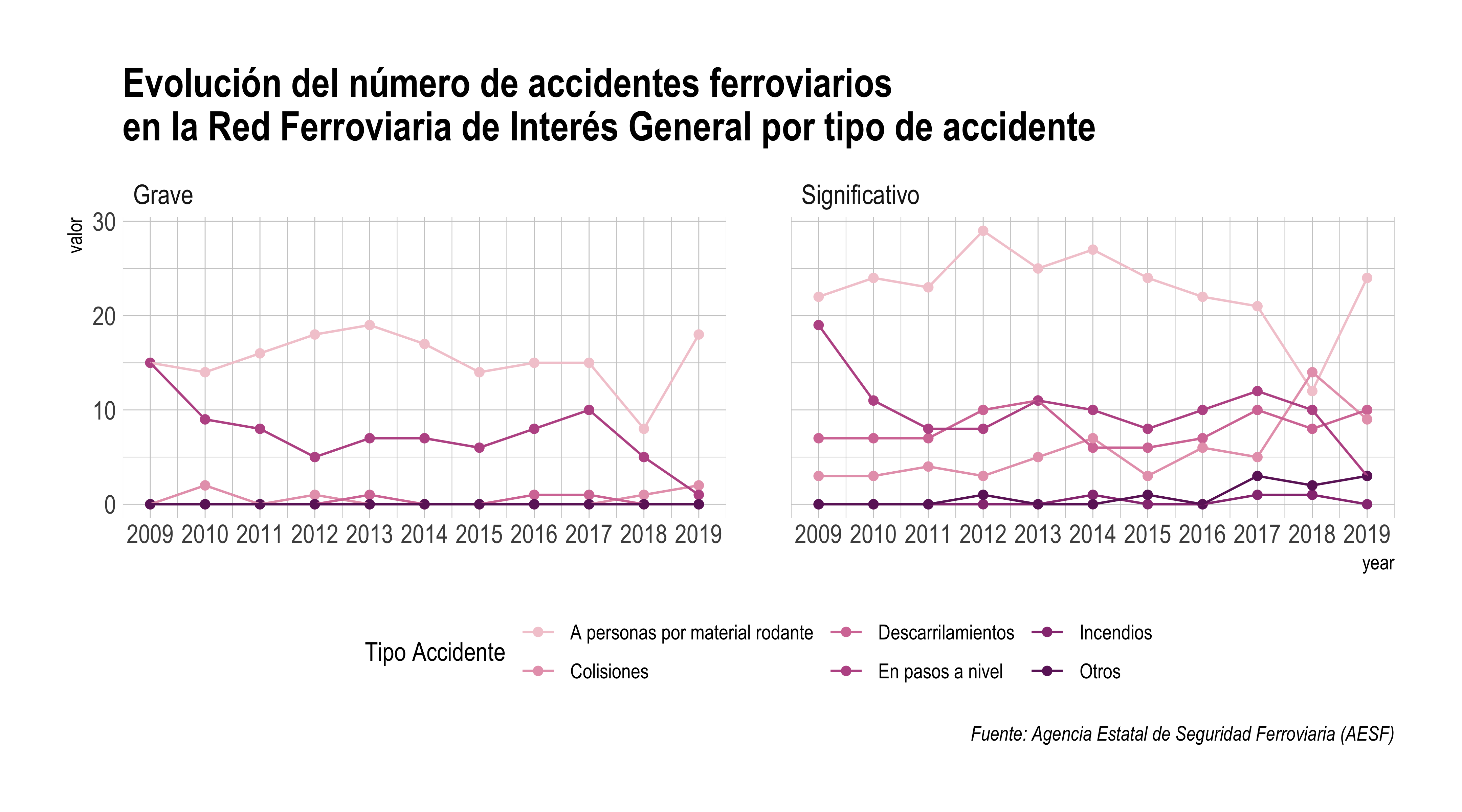
1. Focaliza la información
En el gráfico hay información en exceso, sin un objetivo en particular. Cada punto representa el número de accidentes ferroviarios anual según el tipo de accidente. En total, nuestro ojo está percibiendo 132 valores diferentes, algo muy difícil de procesar y recordar en un futuro. Si nuestro interés es mostrar el descenso del total de accidentes en general, lo primero que deberíamos hacer es acumular la cantidad total por año.
Además, al acumular los puntos cambiamos la geometría de líneas y puntos a áreas. Veamos el resultado.
ggplot(df0, aes(x=year, y=valor, color=nombreTipoAccidenFer, fill=nombreTipoAccidenFer)) +
geom_area() +
scale_x_continuous(breaks=2009:2019) +
scale_color_carto_d(palette = 'Magenta') +
scale_fill_carto_d(palette = 'Magenta') +
facet_wrap('nombreValoracionAcciden') +
theme_ipsum() +
theme(legend.position='bottom') +
labs(title='Evolución del número de accidentes ferroviarios \nen la Red Ferroviaria de Interés General por tipo de accidente', caption='Fuente: Agencia Estatal de Seguridad Ferroviaria (AESF)',
color='Tipo Accidente', fill='Tipo Accidente') 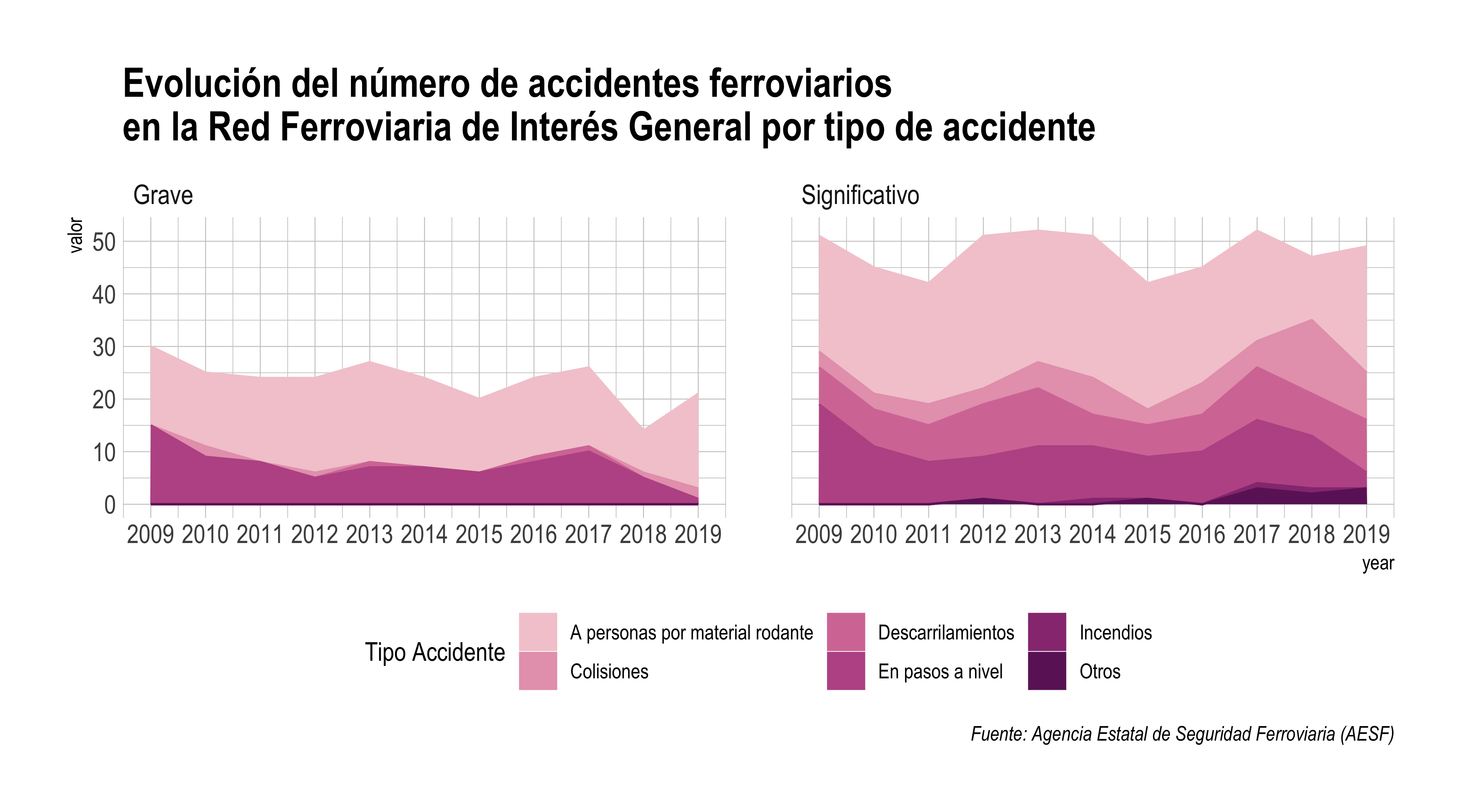
2. Muestra solamente las variables de interés
¿Realmente nos interesa mostrar la diferencia en cuanto a la gravedad accidente? En este caso, no es relevante, por lo que agregaremos el número de accidentes por tipo sin tener en cuenta si se trata de un accidente grave o significativo.
library(dplyr)
df0 %>%
group_by(nombreTipoAccidenFer, year) %>%
summarise(valor:=sum(valor)) -> df1ggplot(df1, aes(x=year, y=valor, color=nombreTipoAccidenFer, fill=nombreTipoAccidenFer)) +
geom_area() +
scale_x_continuous(breaks=2009:2019) +
scale_fill_carto_d(palette = 'Magenta') +
scale_color_carto_d(palette = 'Magenta') +
theme_ipsum() +
theme(legend.position='bottom') +
labs(title='Evolución del total del número de accidentes ferroviarios \nen la Red Ferroviaria de Interés General por tipo de accidente', caption='Fuente: Agencia Estatal de Seguridad Ferroviaria (AESF)', color='Tipo Accidente', fill='Tipo Accidente')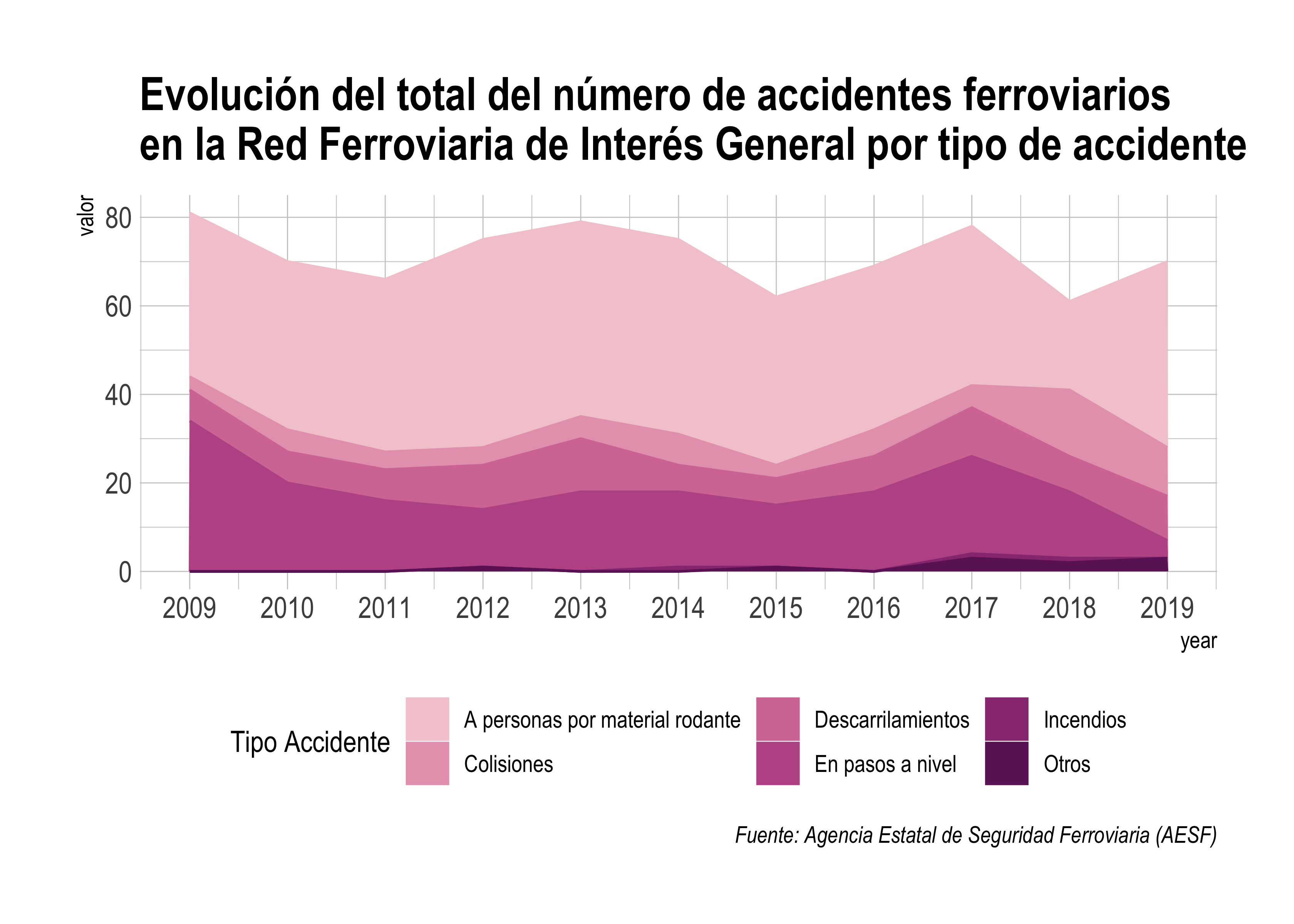
3. Simplifica los datos
Si lo que pretendemos es mostrar el descenso del número de accidentes de tren, no es necesaria mostrar toda la evolución anual, aunque dispongamos de esa información.
df1 %>%
filter(year %in% c(2009, 2019)) -> df2ggplot(df2, aes(x=year, y=valor, color=nombreTipoAccidenFer, fill=nombreTipoAccidenFer)) +
geom_area() +
scale_x_continuous(breaks=c(2009,2019)) +
scale_color_carto_d(palette = 'Magenta') +
scale_fill_carto_d(palette = 'Magenta') +
theme_ipsum() +
theme(legend.position='bottom') +
labs(title='Descenso del total de accidentes ferroviarios \nen la Red Ferroviaria de Interés General por tipo de accidente', caption='Fuente: Agencia Estatal de Seguridad Ferroviaria (AESF)', color='Tipo Accidente', fill='Tipo Accidente')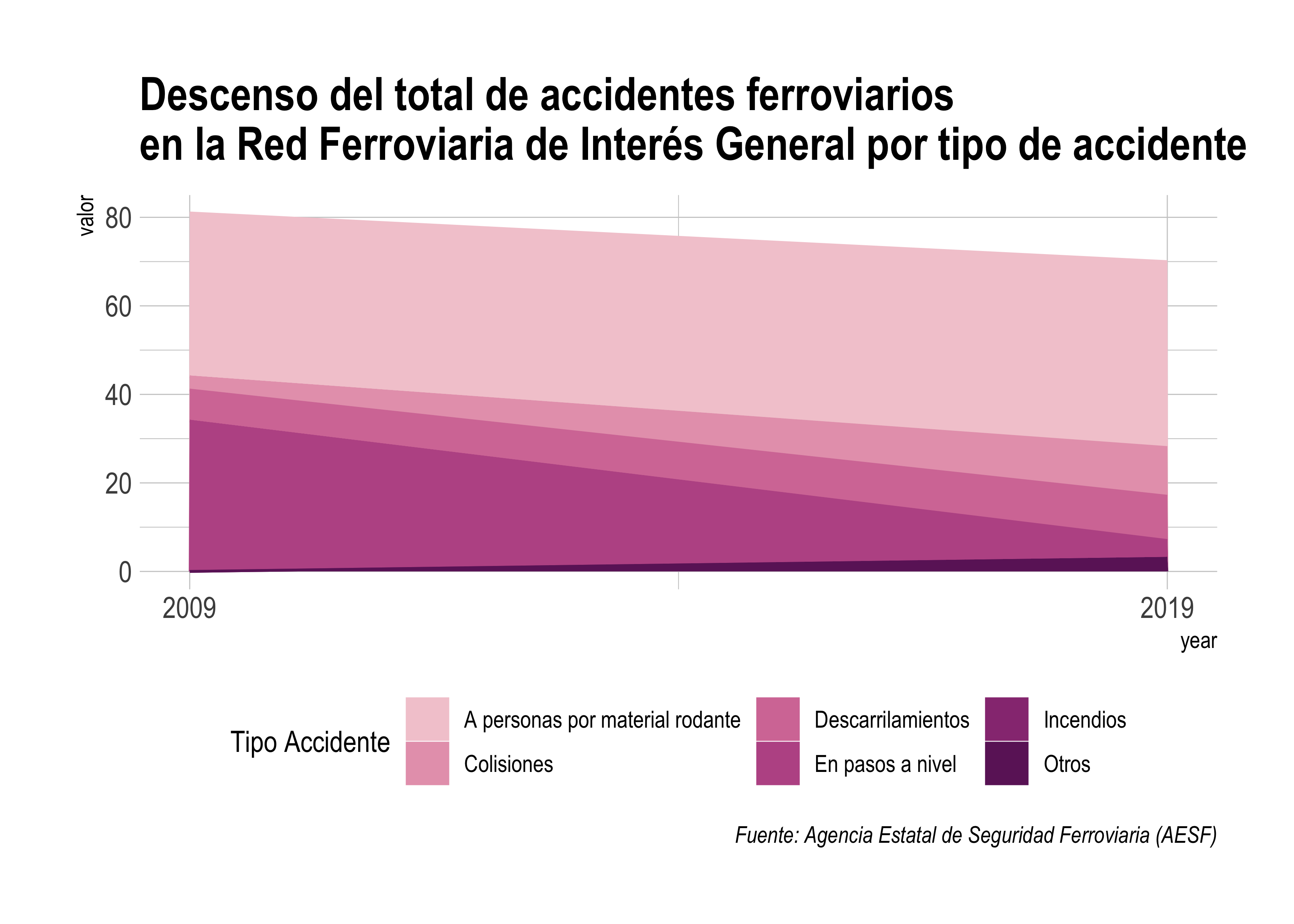
Así se entiende claramente cuál ha sido el descenso en los últimos años, eliminando ruido que pudiera ocasionar los datos de años intermedios.
4. Elimina todo aquello que no aporte valor
El gráfico sigue contienendo elementos que no contribuyen a una estética limpia, como por ejemplo la cuadrícula secundaria de fondo o las etiquetas de los ejes.
Por otro lado, también podemos simplifcar el título y llevar información secundaria al subtítulo.
ggplot(df2, aes(x=year, y=valor, color=nombreTipoAccidenFer, fill=nombreTipoAccidenFer)) +
geom_area() +
scale_x_continuous(breaks=c(2009,2019)) +
scale_color_carto_d(palette = 'Magenta') +
scale_fill_carto_d(palette = 'Magenta') +
theme_ipsum() +
theme(legend.position='bottom',
panel.grid.major.y = element_blank(),
panel.grid.minor = element_blank()) +
labs(title='Descenso de accidentes ferroviarios \nen la Red Ferroviaria de Interés General', subtitle='Comparativa de datos entre 2009 y 2019 por tipo de accidente', caption='Fuente: Agencia Estatal de Seguridad Ferroviaria (AESF)', x='', y='', color='Tipo Accidente', fill='Tipo Accidente')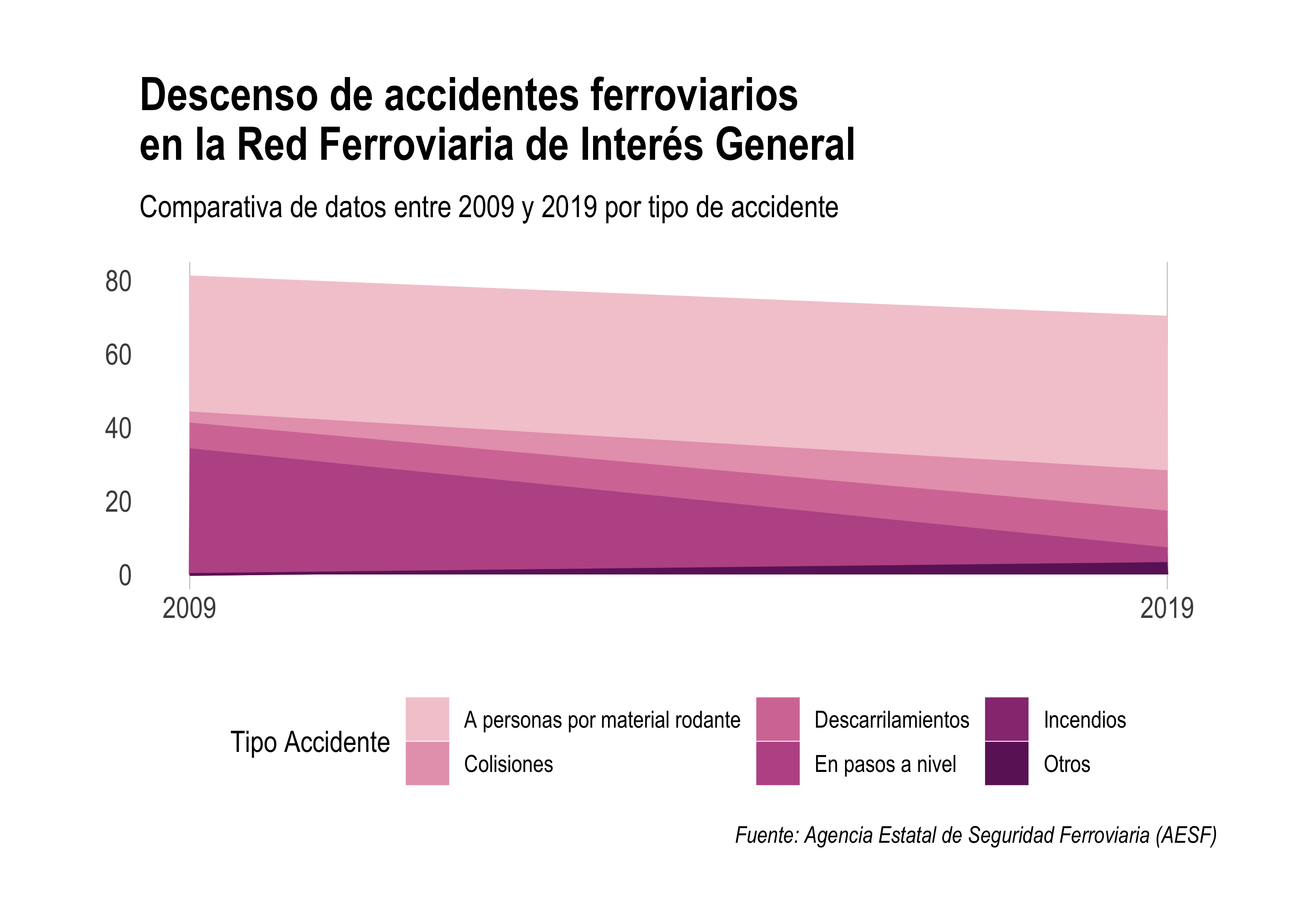
5. Facilita la comprensión del gráfico
Para dar el paso final, necesitaremos reflexionar acerca del diseño del mismo. ¿Qué podría cambiar para hacer el gráfico más comprensible?
Lo primero, el eje vertical no ayuda a entender mejor la información, por lo que mostraremos directamente el valor de cada límite de área y eliminaremos las etiquetas de dicho eje.
Por otro lado, los colores se pueden asignar de manera más eficaz, llevando los colores más oscuros a valores más altos y los más claros dejándolos en las áreas de la base.
df2 %>%
filter(year ==2009) %>%
arrange(valor) %>%
pull(nombreTipoAccidenFer) -> levels_tipo
df2$nombreTipoAccidenFer <- factor(df2$nombreTipoAccidenFer, levels=levels_tipo)
df2 %>%
ungroup() %>%
group_by(year) %>%
arrange(year, nombreTipoAccidenFer) %>%
mutate(cum_valor:=cumsum(valor)) -> df3
df3$nombreTipoAccidenFer <- factor(df3$nombreTipoAccidenFer, levels=levels_tipo[6:1])
ggplot(df3, aes(x=year, y=valor, color=nombreTipoAccidenFer, fill=nombreTipoAccidenFer)) +
geom_area() +
geom_text(data=subset(df3, year == 2009), aes(x=2009, y=cum_valor, label=cum_valor), hjust=1.3) +
geom_text(data=subset(df3, year == 2019), aes(x=2019, y=cum_valor, label=cum_valor), hjust=-0.2) +
scale_x_continuous(breaks=c(2009,2019)) +
scale_color_carto_d(palette = 'Magenta', direction = -1) +
scale_fill_carto_d(palette = 'Magenta', direction = -1) +
theme_ipsum() +
theme(legend.position='bottom',
panel.grid.major.y = element_blank(),
panel.grid.minor = element_blank(),
axis.text.y= element_blank()) +
labs(title='Descenso de accidentes ferroviarios \nen la Red Ferroviaria de Interés General', subtitle='Comparativa de datos entre 2009 y 2019 por tipo de accidente', caption='Fuente: Agencia Estatal de Seguridad Ferroviaria (AESF)', x='', y='', color='Tipo Accidente', fill='Tipo Accidente') -> p5
p5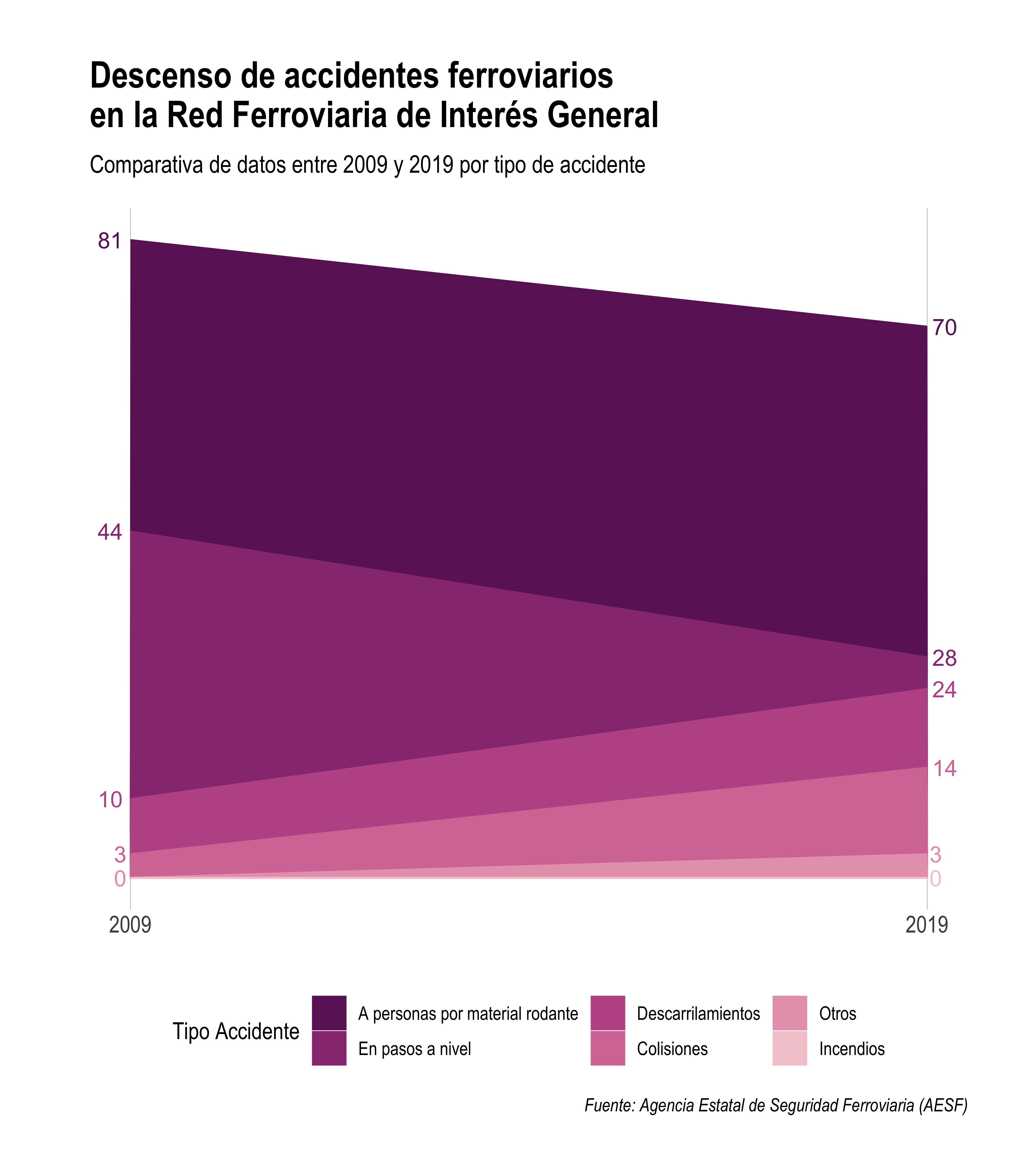
Conclusiones
Finalmente, hemos pasado de un gráfico interesante pero sin un objetivo concreto, a una visualización mucho más centrada en el concepto que se deseaba transmitir.
Primero, focalizando la información y simplificando los datos, centrándonos en lo que se pretendía trasladar al lector; y segundo, analizando aquellos elementos del diseño que podían ser mejorados.
Este es el resultado final. Aquí, se puede apreciar el cambio de un gráfico que simplemente muestra un conjunto de datos, a un gráfico más trabajado, pensado para dar un mensaje en particular.
library(patchwork)
p0 + p5 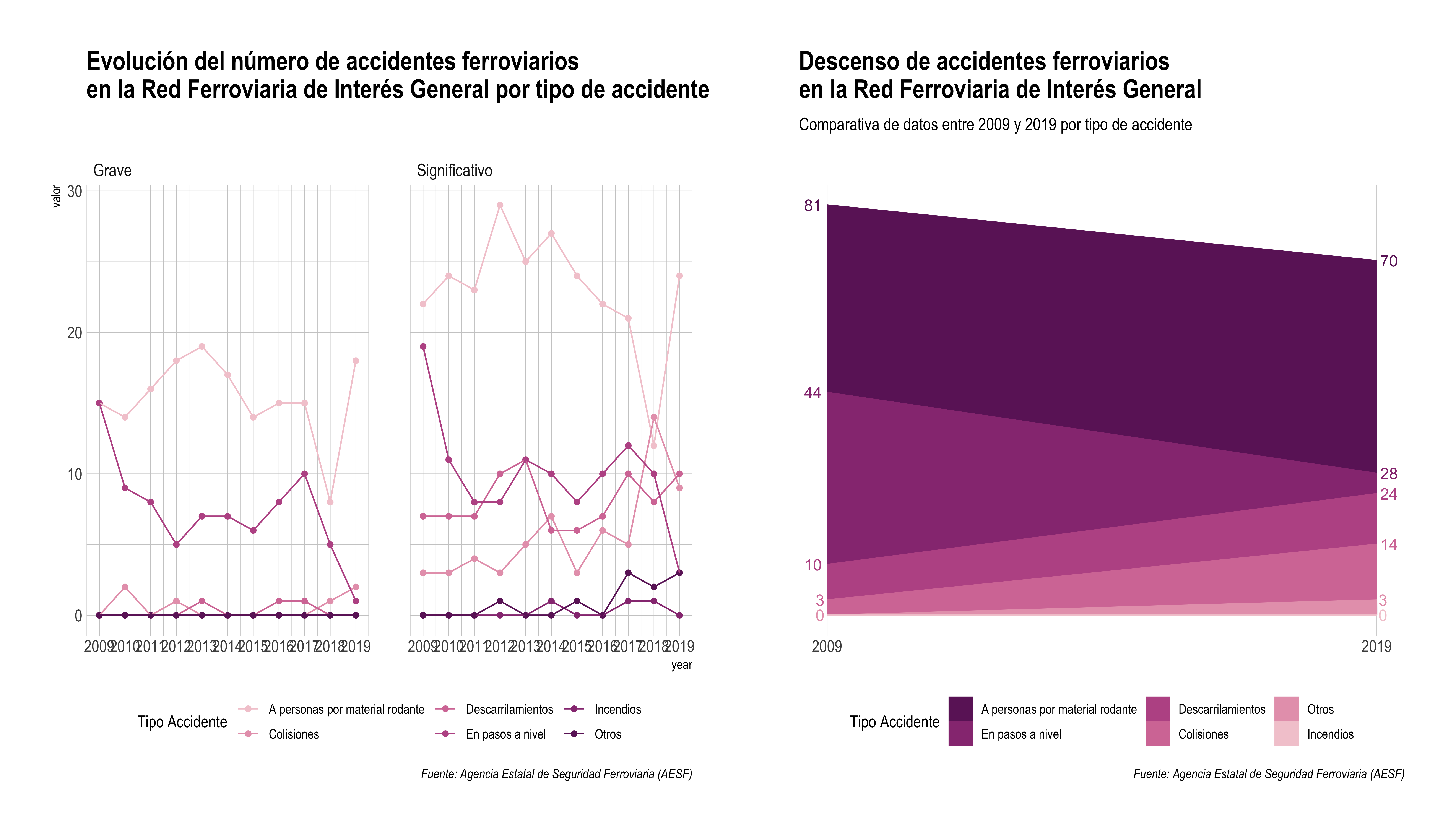
Contenido relacionado