library(dplyr)
library(data.table)
library(readr)
library(ggplot2)
epa2020 <- read_csv("epa2020.csv")La EPA o Encuesta de Población Activa es una de las encuestas realizadas por el INE más importantes de nuestro país, pues trata de medir el estado del mercado laboral en España. Se viene realizando desde 1964 y conserva la metodología de 2005. En concreto, la muestra de la EPA es de 65.000 familias al trimestre, que el propio INE estima como 160.000 personas.
Como es sabido, el paro es uno de los factores sociales que más impacto tienen sobre la economía, por ello es fundamental entender y saber representar los resultados de este tipo de encuestas. En el post de hoy veremos cómo visualizar los datos de la EPA con R, en concreto una de las preguntas más interesantes:
Razones por las que no trabajó, teniendo empleo. EPA 2020, INE
Datos
Los resultados de las encuestas son facilitados por el INE en ficheros de microdatos. Estos ficheros están preparados en formato csv o txt y cada uno de las filas contiene un registro individual de la encuesta con los valores que toma cada variable. El enlace para la descarga de los microdatos se puede consultar aquí. Además, el INE proporciona scripts para cargar los datos directamente con los softwares estadísticos más comunes como son R, STATA, SPSS o SAS.
En nuestro caso, partimos de un csv ya preparado por @javimartzs (gracias 😉) que contiene la unión de cuatro trimestres de la EPA 2020. Para leerlo utilizaremos la librería readr de R, en concreto la función read_csv(), aunque valdría cualquier otra función que permita leer ficheros csv.
Preparación de los datos
A continuación, preparamos los datos para representar las respuestas a la pregunta de interés. En este caso hemos elegido “Razones por las que no trabajó, teniendo empleo”. Cabe destacar que esta pregunta sólo es contestada por aquellas personas mayores de 16 años que no trabajaron en la semana de referencia, no ayudan en un negocio familiar, y además tienen empleo.
Por tanto, al calcular el porcentaje de respuestas debe tenerse en cuenta que se hace sobre ese subconjunto concreto y que no se refiere ni al total de encuestados, ni mucho menos, al total de la población (recordemos que sólo estamos visualizando los resultados de la encuesta y no sacando conclusiones sobre la población total en sí).
epa2020 %>%
filter(!is.na(RZNOTB)) %>%
group_by(RZNOTB, FECHA) %>%
summarise(n = n()) %>%
group_by(FECHA) %>%
mutate(pct = n/sum(n)) %>%
mutate(RZNOTB:=as.factor(RZNOTB),
Trimestre:=as.factor(FECHA))-> dfCon la librería **dplyr**, la transformación de los data frames y cálculo de nuevas variables es muy sencillo, además de ser similar a otros lenguajes para hacer consultas sobre bases de datos como SQL.
Leyenda
La leyenda constituye otros de los factores esenciales en estos gráficos pues aportan la información concreta de cada una de las respuestas. Para ello, hemos generado a partir del diseño de registro, una tabla con el código de las respuestas y su descripción.
| Código | Descripción |
| 1 | Vacaciones o dias de permiso |
| 2 | Permiso por nacimiento de un hijo |
| 3 | Excedencia por nacimiento de un hijo |
| 4 | Enfermedad, accidente o incapacidad temporal del encuestado |
| 5 | Jornada de verano, horario variable, flexible o similar |
| 6 | Actividades de representación sindical |
| 7 | Nuevo empleo en el que aún no había empezado a trabajar |
| 8 | Fijo discontinuo o trabajador estacional en la época de menor actividad |
| 9 | Mal tiempo |
| 10 | Paro parcial por razones técnicas o económicas |
| 11 | Se encuentra en expediente de regulación de empleo |
| 12 | Huelga o conflicto laboral |
| 13 | Haber recibido enseñanza o formación fuera del establecimiento |
| 14 | Razones personales o responsabilidades familiares |
| 15 | Otras razones |
| 0 | No sabe |
Tabla de códigos y descripciones de las respuestas a la pregunta: “Razones por las que no trabajó, teniendo empleo” de la EPA 2020
tabla <- fread('epa_table')Gráfico con ggplot2
Finalmente, realizamos un gráfico de líneas con ggplot2, una de las librerías por excelencia para visualización de datos con R.
Trataremos cada una de las respuestas de la encuesta como una serie diferente. Para ello llevaremos la variable RZNOTB al grupo y al color de la estética. Se aconseja que la variable sea de tipo factor, ya que al tratarse de una variable categórica codificada con números, ggplot por defecto la tomará como una variable continua.
También transformamos la variable FECHA para que en el eje de las X se marque exactamente el punto del trimestre. Existen otras formas de cambiar las marcas del eje, como por ejemplo modificando los breaks y labels del mismo con la función scale_x_date().
Por último, recordamos que siempre debemos especificar la fuente de datos, en este caso el INE, y añadir título y subtítulo que aclare la información que se está representando.
df %>%
ggplot(aes(x=Trimestre, y=pct, group=RZNOTB, color=RZNOTB)) +
geom_line() +
geom_point() +
theme_minimal() +
scale_y_continuous(labels = scales::percent, name = ) +
scale_color_discrete(name = 'Razón Paro', labels = tabla$Descripción) +
labs(title='Razones por las que no trabajó, teniendo empleo',
subtitle='Todas las personas de 16 y más años que no trabajaron la
semana de referencia, ni ayudan en el negocio familiar,
y tenían empleo.',
caption='Fuente: Encuesta de Población Activa 2020 - INE')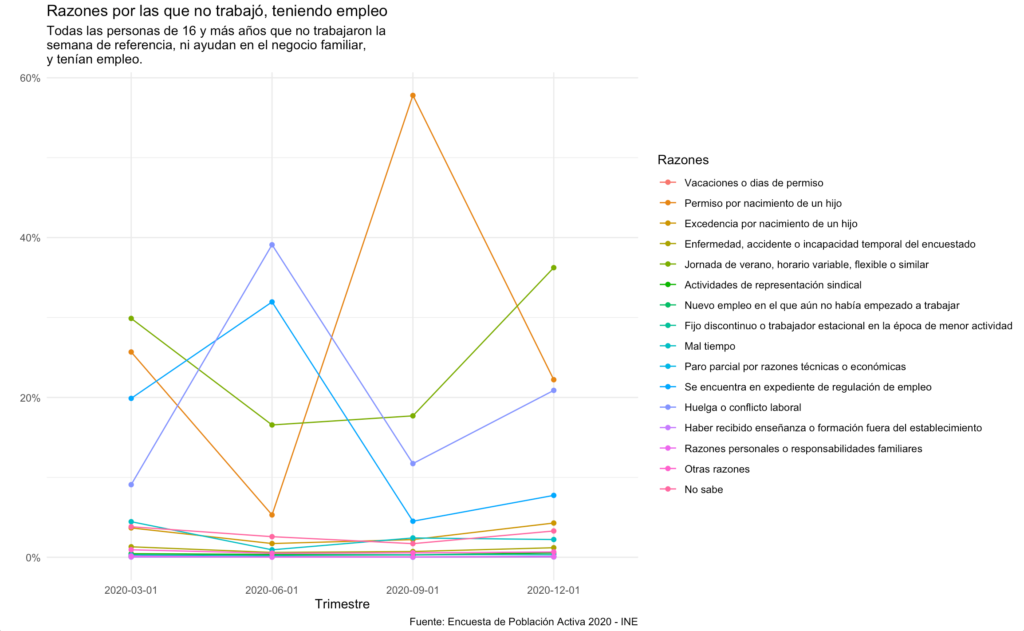 Como vemos, es relativamente sencillo visualizar esta clase de datos y por ello desde aquí, animamos a todos aquellos interesados a practicar la representación de resultados de encuestas como esta, para entender mejor lo que ocurre en la sociedad.👩💻👨💻
Como vemos, es relativamente sencillo visualizar esta clase de datos y por ello desde aquí, animamos a todos aquellos interesados a practicar la representación de resultados de encuestas como esta, para entender mejor lo que ocurre en la sociedad.👩💻👨💻
Contenido relacionado


